
Explore AI’s role in software development, from coding and testing to AI-powered system design.


The fastest way to blow up your runway with a Claude-powered product is to ship Sonnet on every request and never touch caching. The fastest way to fix it is four moves: cache your system prompts, route easy calls to Haiku, trim context aggressively, and push anything non-interactive through the Batch API. Done well, Claude API cost optimization can cut a production bill by 60–90% without users noticing. This guide walks through the per-token math behind each tactic so you can model burn before launch instead of after your first invoice shock.
The numbers below use Anthropic’s public list pricing as of late 2024. Prices change; the ratios between models and the structure of the optimizations don’t.
Table of Contents
Start with the table. Everything downstream is a multiplier on these base rates.
| Model | Input ($/MTok) | Output ($/MTok) | Cache write | Cache read |
|---|---|---|---|---|
| Claude 3.5 Haiku | $0.80 | $4.00 | $1.00 | $0.08 |
| Claude 3.5 Sonnet | $3.00 | $15.00 | $3.75 | $0.30 |
| Claude 3 Opus | $15.00 | $75.00 | $18.75 | $1.50 |
Two ratios to memorize. Output is 5× input across every Claude model. Cache reads are 10% of normal input. That second number is the single biggest lever most teams ignore.
A worked example. Say your support agent uses Sonnet with a 4,000-token system prompt plus tool definitions, pulls in 2,000 tokens of conversation history, and writes a 500-token reply. Naive cost per turn: (6,000 × $3 + 500 × $15) / 1M = $0.0255. At 50,000 turns a month, that’s $1,275. Not catastrophic, but every optimization below stacks on this baseline.
Prompt caching lets Claude store a prefix of your prompt (system message, tool definitions, few-shot examples, retrieved documents) and reuse it across requests at 10% of the normal input price. You pay a 25% premium on the first write, then read at one-tenth cost for the next 5 minutes (or 1 hour on the extended TTL).
Back to the support agent. That 4,000-token system prompt is identical on every request. Cache it once, and per-turn input cost on the cached portion drops from $0.012 to $0.0012. Across 50,000 turns, the system prompt alone goes from $600 to $60. Add cache writes (one per 5-minute window, maybe 8,640 per month at most), and you’re looking at roughly $93 instead of $600-a $507/month win on a single component.
What’s cacheable in practice:
Two practical traps. First, the cache is keyed on an exact prefix match. If you splice a per-user variable into the middle of your system prompt, you’ve broken caching for everything after it. Put dynamic content at the end. Second, the 5-minute TTL resets on every cache hit, so a busy endpoint keeps the cache hot for free. Quiet endpoints (nightly jobs, low-traffic tenants) may want the 1-hour TTL even though the write premium is steeper.
Sonnet is roughly 3.75× the cost of Haiku on both input and output. Opus is 5× Sonnet. If you’re running Sonnet on every call because it’s the “smart default,” you’re overpaying for the 60–70% of requests that Haiku handles fine.
A routing pattern that works in production:
Real numbers on a 50,000-turn month. Assume 65% of turns route to Haiku at $0.005/turn and 35% to Sonnet at $0.0255/turn. Blended cost: $0.0163/turn, $815/month. Versus all-Sonnet at $1,275, that’s a 36% cut layered on top of caching. Stack both and you’re at roughly $300/month for the same product.
One caveat. Routing only pays off if your classifier is accurate. Spend a weekend building an eval set of 200–500 labeled requests and measure routing accuracy before you ship. We’ve seen founders deploy routing logic that mis-routes 20% of complex requests to Haiku, save 30% on tokens, and lose customers because the agent suddenly feels dumb. The savings aren’t worth the churn.
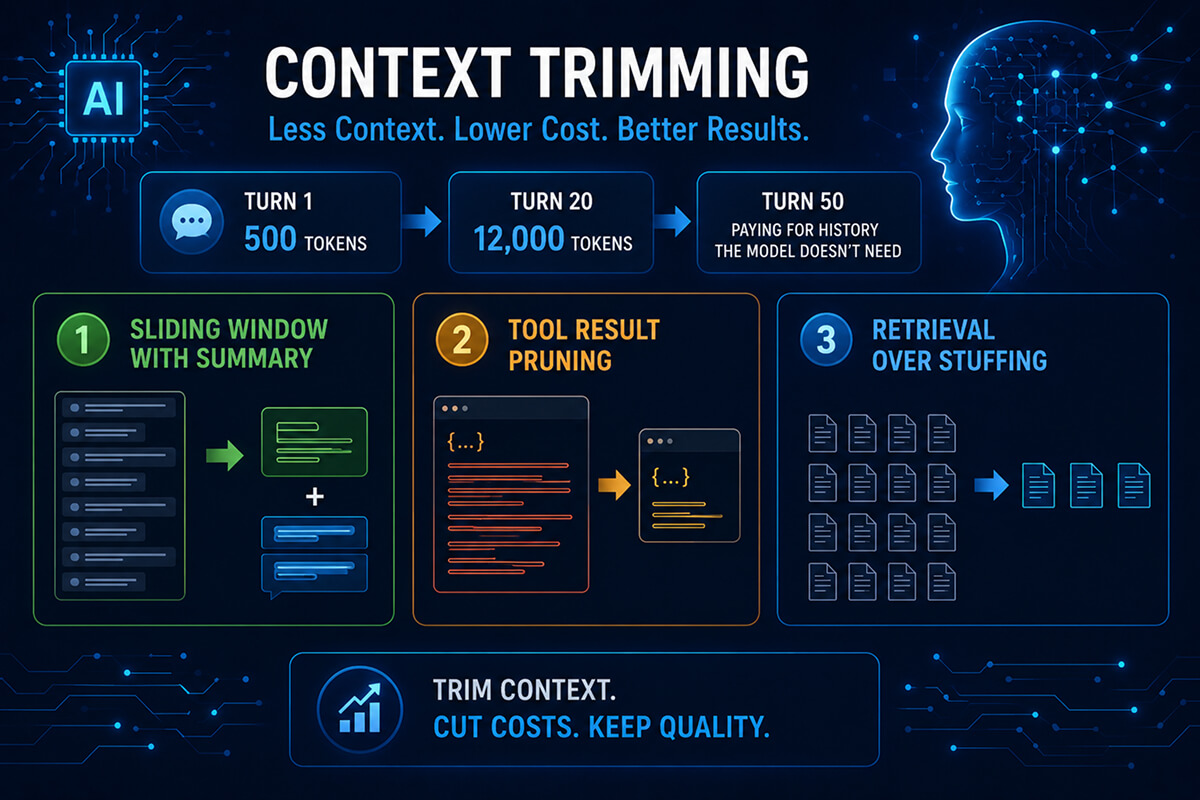
Conversation history is the line item that grows silently. Turn 1 sends 500 tokens of history. Turn 20 sends 12,000. By turn 50 you’re paying Sonnet input rates on content the user wrote 30 minutes ago and the model doesn’t need anymore.
Three techniques that compose well:
Keep the last N turns verbatim (typically 4–8). Summarize everything older into a 200–400 token block that lives at the top of the message array. Refresh the summary every 10 turns. A 12,000-token history collapses to roughly 2,500 tokens, cutting per-turn input cost by ~80% on long sessions.
Tool calls produce verbose JSON. A database query might return 8,000 tokens of rows when the agent only needed the top 3 to answer. Truncate or post-process tool results before passing them back into the conversation. Better: have the tool itself return a compact view by default and a “verbose” mode the agent can request.
If you’re injecting documents into context for RAG, retrieve only the top 3–5 chunks instead of the top 20. Re-rank if quality drops. Most “long context” cost overruns are RAG pipelines tuned for recall when precision would have served the same answer at one-fifth the price.
Anthropic’s Batch API processes requests asynchronously within 24 hours at 50% off both input and output. For any workload that isn’t user-facing in real time, this is a flat 2× efficiency gain with no engineering trade-offs beyond an async pattern.
Workloads that belong in batch:
A concrete case. A B2B sales-intel startup we worked with was scoring 80,000 new company records a week on Sonnet, paying about $4,800/month. Moving the entire scoring pipeline to Batch-same model, same prompts, just async-dropped it to $2,400. They also stacked prompt caching on the scoring prompt and got to $1,100. Two weeks of engineering for a $44K annual saving.
Founders fixate on input optimization and forget the output side, where every token costs 5× more. A model that writes a 1,200-token answer when 300 would do is quietly tripling your bill on the most expensive side of the ledger.
Tactics that work:
You can’t optimize what you can’t see. Before applying any of the above, wire up per-request logging that captures: model, input tokens, output tokens, cache read tokens, cache write tokens, latency, and a request-type tag (intent, endpoint, customer tier). Pipe it to whatever you use-Datadog, a Postgres table, even a daily CSV.
Within a week you’ll have a Pareto chart showing which 3–5 request types account for 80% of spend. Optimize those first. We’ve seen teams spend two sprints shaving tokens off a flow that represented 4% of their bill while a single misconfigured webhook was burning $3,000/month in retries against Opus.
Put it together. Imagine a Claude-powered onboarding agent for a B2B SaaS, 2,000 active users, average 15 agent turns/user/month, 30,000 turns total.
| Configuration | Per-turn cost | Monthly cost |
|---|---|---|
| Naive Sonnet, no caching | $0.0255 | $765 |
| + Prompt caching | $0.0145 | $435 |
| + Haiku routing (65/35 split) | $0.0088 | $264 |
| + Context trimming (-40% input) | $0.0061 | $183 |
| + Batch for nightly recap (20% of turns) | $0.0053 | $159 |
Same product, same model quality where it matters, 79% lower bill. Run this exercise on your own assumptions before you commit to a pricing plan or a fundraise model. The difference between $159/month and $765/month at scale is the difference between gross margins that look like a SaaS business and margins that look like a reseller.
Cost discipline isn’t about being cheap. It’s about keeping enough margin to invest in the parts of the product that actually differentiate-better evals, better tools, faster iteration-instead of subsidizing token waste.
Claude Development
Jun 15, 2026
Explore AI’s role in software development, from coding and testing to AI-powered system design.
Claude Development
Jun 12, 2026
Claude multi-agent systems with orchestrator-worker, hierarchical, and swarm patterns for research and sales.

Claude Development
May 18, 2026
Explore leading AI development agencies in the USA and their innovative AI solutions.