Discover what makes an AI development agency in Singapore stand out in the growing AI market.

Most teams reach for Claude multi-agent systems too early. A single agent loop with good tools and a tight prompt will outperform a three-agent orchestration on 80% of real tasks-it’s cheaper, easier to debug, and faster. Multi-agent architectures pay off when work is genuinely parallelizable, when one context window can’t hold the problem, or when subtasks need different tools, models, or permissions. This post walks through the three patterns we actually ship in production-orchestrator-worker, hierarchical, and swarm-with concrete examples, the failure modes to plan for, and a decision rule for when each is worth the complexity.
Table of Contents
Before any pattern discussion, the honest baseline: Claude Sonnet 4 with tool use, a system prompt under 2,000 tokens, and a loop that runs until the model emits a stop signal will handle most internal tools. Customer support triage. Pulling data from three SaaS APIs and writing a summary. Reviewing a PR against a style guide. These don’t need multiple agents.
The signs you’ve outgrown a single loop are specific. Context window pressure-you’re stuffing 80k+ tokens of search results into one conversation and quality degrades. Latency-the task is embarrassingly parallel and running it serially takes minutes when it could take seconds. Permission boundaries-one part of the workflow needs production database access and another shouldn’t have it. Specialization-a coding subtask wants Claude Opus while a classification step is fine on Haiku.
If none of those apply, stop reading and ship the single agent. If one or more applies, the patterns below are your toolkit.
The orchestrator-worker pattern is the workhorse of production Claude multi-agent systems. One agent-the orchestrator-receives the task, decomposes it into independent subtasks, spawns workers to handle each, and synthesizes the results. Workers don’t talk to each other. They report back to the orchestrator.
Anthropic’s own research agent, described in their engineering blog, runs this pattern. A lead Claude agent reads a research query like “compare the go-to-market motion of Ramp, Brex, and Mercury,” plans the investigation, and dispatches three or four subagents to run searches in parallel. Each subagent has its own context window, runs maybe 10-20 tool calls, and returns a structured summary. The orchestrator stitches the summaries into a final answer.
Three things make this pattern earn its keep:
Cost is the obvious one. A multi-agent research run can use 10-15x the tokens of a single-agent attempt at the same query. Anthropic has been transparent that their research feature is reserved for tasks where that tradeoff is worth it-deep investigation, not “what’s the weather.” If your task takes a single agent 5,000 tokens to solve, an orchestrator-worker version might burn 60,000. You need the output to be worth that.
The second failure mode is task decomposition. Orchestrators are sometimes overconfident splitters. They’ll fan out a task into six subtasks when two would do, or split work in ways that create dependencies between workers (which then can’t run in parallel anyway). The fix is a constrained planning prompt: give the orchestrator a clear schema for what a “subtask” looks like, a maximum fan-out, and examples of good vs. bad decompositions.
Hierarchical systems extend orchestrator-worker to multiple levels. A top-level agent delegates to mid-level agents, each of which has its own pool of workers. It’s the org chart pattern, and you reach for it when subtasks themselves need decomposition.
A sales ops example we’ve built: a “deal desk” agent receives an inbound opportunity from Salesforce. It delegates to three mid-level agents-Pricing, Legal Review, and Technical Fit. The Pricing agent then spawns its own workers: one pulls comparable deals from the data warehouse, one checks current discount approval thresholds, one runs margin math. The Legal Review agent runs workers that check the prospect’s MSA against a redlines library and flag deviations. The Technical Fit agent dispatches workers to check integration compatibility, security questionnaire history, and infrastructure requirements.
This is six to nine Claude calls running concurrently under three mid-level coordinators under one top-level agent. A human salesperson would take a day. The hierarchical system finishes in under three minutes.
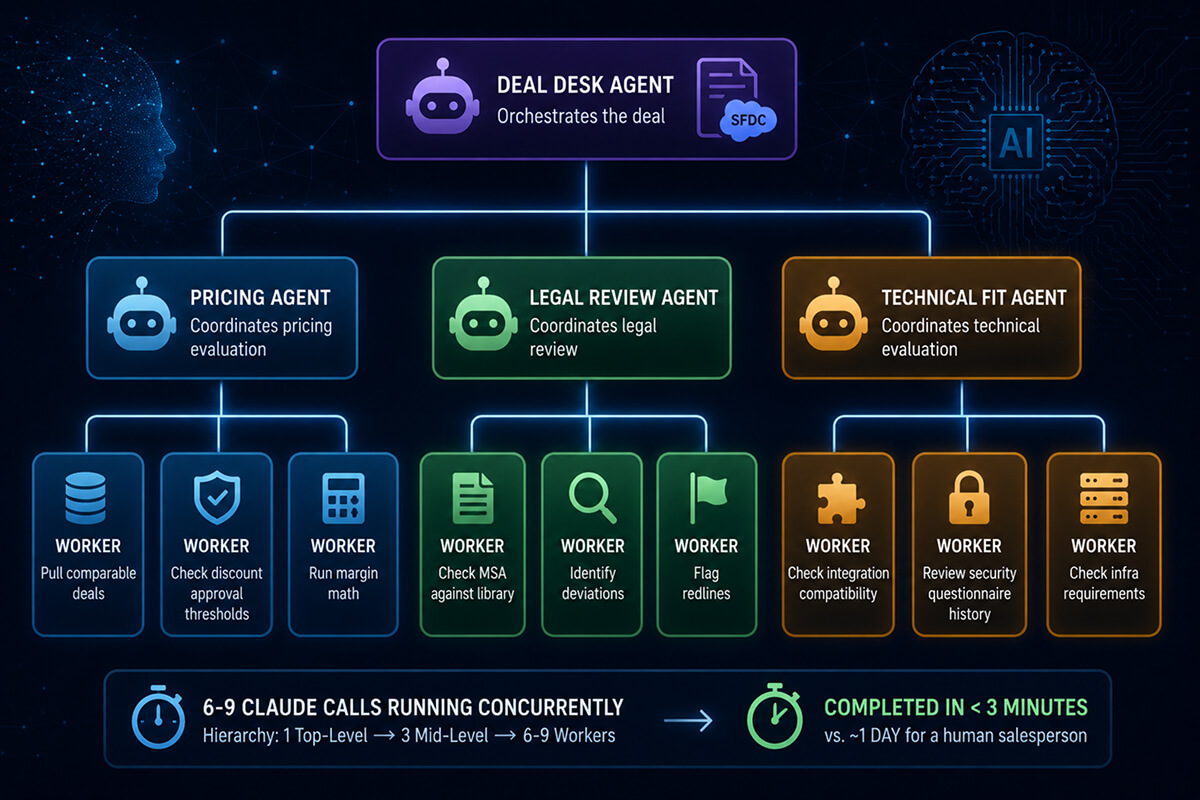
Hierarchy buys you two things flat orchestration can’t:
Hierarchical systems are hard to debug. When a top-level agent returns a wrong answer, the trace might involve 15 Claude calls across three levels. You need real observability-Langfuse, LangSmith, or a custom tracing setup-before you build anything beyond two levels. Without it, you’ll spend more time diagnosing than the system saves.
Hierarchy also amplifies the cost problem. Each layer adds coordination overhead: the planning tokens, the result synthesis tokens, the back-and-forth. Three layers can easily 30x the token usage of a single agent on the same input.
Swarm patterns drop the orchestrator entirely. Agents are peers. Each one handles part of a task, then hands off to whichever peer is best suited for the next step. OpenAI’s Swarm library popularized the term, but the pattern works fine with Claude-it’s just a control flow choice, not a model feature.
The canonical example is customer support. A “Triage” agent receives an inbound message. If it’s a billing question, it hands off to the Billing agent. The Billing agent might discover the underlying issue is a failed integration and hand off to the Technical agent. The Technical agent resolves it and hands back to a Wrap-Up agent that writes the response and updates the ticket.
No agent in this chain has the full system in its head. Each one has a focused prompt, a narrow tool set, and a list of peers it can hand off to. The handoff itself is just a tool call “transfer_to_billing(context)” that the runtime intercepts to swap agents.
Swarms are right when the routing logic is genuinely dynamic and you don’t know the workflow shape up front. A support ticket might bounce between two agents or six. A research task might stay in one specialty or pull in three. Trying to plan that fan-out from a central orchestrator is brittle. Letting agents route to each other based on what they discover is more natural.
They’re also lighter weight than hierarchical systems. There’s no planning overhead, no synthesis step. Each agent does its job and passes the baton. Token usage stays close to what a single agent would burn-you’re just swapping system prompts between turns.
Swarms can loop. Agent A hands off to Agent B who decides the issue belongs back with Agent A. We’ve seen this in early support deployments-a Triage agent and a Billing agent ping-ponging because neither was confident enough to commit. You need explicit guards: a max-handoff counter, a “no return to previous agent” rule, or a fallback escalation path to a human or a default resolver.
The other risk is fragmented context. Each agent only sees what the previous one passed forward. If Agent A summarizes badly, Agent C is working from a lossy view of the original request. The mitigation is a shared scratchpad-a structured object that travels with the handoff and accumulates rather than replaces context.
Here’s the decision rule we use on new projects:
| Pattern | Use when | Avoid when | Typical token multiplier vs. single agent |
|---|---|---|---|
| Single agent loop | Task fits in one context window and runs in under 30s | Need parallelism or specialization | 1x |
| Orchestrator-worker | Parallel subtasks, independent, returning to one synthesizer | Subtasks are sequential or depend on each other | 8-15x |
| Hierarchical | Subtasks themselves decompose; permission scoping matters | You don’t have tracing infrastructure | 15-30x |
| Swarm | Dynamic routing, unclear workflow shape, conversational handoffs | Risk of loops; need strict latency budgets | 1.2-3x |
The pattern is maybe 30% of the outcome. The other 70% is implementation hygiene:
Structured handoffs. Don’t let agents pass free-form text between each other. Define a schema-a JSON object with fields like task, context, prior_findings, constraints. Pydantic or Zod on the runtime side. Claude is excellent at producing structured output when you ask for it.
Tool budgets per agent. Every subagent should have a max tool call count. Without it, a worker can spiral and burn 50 calls on a task that should take 5. We default to 10 tool calls per worker, 20 for orchestrators.
Model tiering. Run orchestrators on Sonnet or Opus. Run workers on Haiku where possible. For a research task, the planning needs strong reasoning but the search-and-summarize loop is fine on a cheaper model. This single change can cut costs 60-70% with minimal quality loss.
Observability from day one. Trace every agent call with inputs, outputs, tool calls, and token counts. Without this, debugging a 12-call hierarchical run is guesswork. We use Langfuse on most builds; the integration is a few lines.
Failure semantics. Decide what happens when a worker fails. Retry once? Skip and continue? Escalate? Pick a policy per subtask type and encode it in the orchestrator’s logic, not the prompt.
If you’re starting a new Claude multi-agent project, the build order that wastes the least time:
The teams that get burned on multi-agent builds almost always skipped step one. They designed an elegant hierarchy in a whiteboard session, built it for six weeks, and then discovered that a single agent with better tools would have done the job in two. Patterns are tools, not goals. The goal is the user-visible outcome-faster research, cleaner support resolution, better-qualified deals-and the simplest architecture that delivers it wins.
Claude Development
Jul 23, 2026
Discover what makes an AI development agency in Singapore stand out in the growing AI market.

Claude Development
Jul 1, 2026
Explore leading generative AI development agencies in the USA, their services, and success stories.

Claude Development
Jun 29, 2026
Model Context Protocol : what it replaces, how it speeds AI MVPs, & production-ready integrations today.